최근 로봇 팔 매니퓰레이터의 모션을 만들어내는 기법으로 강화학습과 생성형 모델을 이용한 논문에 대해서 공부하고 있다. 학부 전공 때 인공지능과 관련된 과목은 개설되지않아 기초부터 공부하고 있지만 필요한 부분만 최대한 발췌해서 공부하려고 하는 중이다.
강화학습에는 많은 종류가 있지만 그 중에서 논문에서 사용 중인 'Deep Q Learning'에 대해서 간단하게 정리해보려고 한다.
강화학습(Reinforcement Learning)
강화학습이란, S = state(상태), A = action(행동), R = reward(보상)으로 이루어져 있다. 주어진 환경에서 어떤 행동을 해야할지에 대해 선택하는 과정을 인공지능(Neuralnet)을 이용해서 학습을 시켜 최적화하는 과정을 의미한다.
다음 행동으로 좋은 선택을 하면 높은 보상을 제공하고 나쁜 선택을 하면 낮은 보상을 제공해서 나쁜 선택을 할 확률을 낮추고 좋은 선택을 할 확률을 증가시켜주는 알고리즘을 가지고 있다.
예를 들어, 상대방에게 총을 통해 목표를 맞추는 FPS 게임을 생각해보자. 이 경우에는 총알을 맞는 행동을 하면 낮은 점수, 총알을 피하거나 맞지 않는 행동을 하면 높은 점수를 제공함으로써 행동을 선택할 때 총알을 피하는 행동을 할 수 있도록 유도하는 알고리즘을 만들게 된다.


위 그림의 상태를 state, $s_1$이라고 하면 A는 B에게 피격을 당할 수 있는 상황에 놓여있다. 이 상황에서 A가 엄폐물 뒤로 숨게되면 높은 점수를 보상으로 제공하고 엄폐물이 아닌 다른 방향으로 이동하게되면 여전히 피격을 당할 수 있기 때문에 낮은 점수를 보상으로 제공하게 된다.
또는 사람의 인생을 예로 들면 우리는 항상 나에게 가장 좋은 방향으로 보상을 최대화할 수 있게 행동하고 선택한다. 대학교에 진학하고 나에게 필요한 전공수업을 들으며 좋은 회사에 취업하거나 대학원에 진학하는 등 모든 행동이 나에게 좋은 reward를 받는 것에 기반한다고 예를 들 수 있다.
Deep Q Learning(DQN)

위 그림은 Deep-Q Learning(DQN)의 구조를 쉽게 이해할 수 있게 도식화한 형태이다.
1. 상태(state)에 대한 정보를 제공해주어야한다. 게임이라면 Pixel에 대한 정보일 것이고 이미지 정보라면 2D 혹은 3D Vector의 형태로 주어지게 될 것이다. 제공한 정보를 Input으로 넣어주기위해 데이터를 전처리하는 과정을 거쳐 Input으로 입력된다.
(*지금 공부하고 있는 논문은 2D point cloud를 통해 이미지 정보를 제공하며 추후에는 3D point cloud까지 제공하게 된다.)
2. Input으로 현재 상태($s_0$)에 대한 정보를 전처리를 통해 제공하게되면 다음 상태로 이동하기위해 어떠한 행동($a_0$)을 취하게 된다. 그 이후 행동을 취한 다음의 상태($s_1)를 업데이트 하게 되면 하나의 루프가 끝나게 된다.
그렇다면 위에 나타난 Q-Value와 Ai, Reward는 언제 제공되어지는 것인지 알고 싶어지게 된다.
3. 1,2를 통해 행동을 진행했으면 그 결과를 바탕으로 Ai(Policy)가 $s_0$에서 각각의 행동($a_t$)에 대한 Q-value를 지정하게 된다. 이 때 Q-value를 지정하기 위해 사용되는 함수를 Q-Function이라 한다. (Q(s,a)의 형태를 가진다)
4. 지정된 Q-value를 참고해서 Q값이 최대가 되는 행동을 하기위한 최적화(train)을 진행하게 된다.
위에 서술한 순서대로 DQN의 알고리즘은 구성되어 있으며 작동하게 된다.
Bellman Equation
Q-Function을 최적화하기위해 사용하는 방정식은 아주 오래 전에 완성되어있는 '벨만 방정식 (Bellman Equation)'을 사용하며 그 수식은 다음과 같다.
$$Q(s,a)+\alpha (r+\gamma max_{a'}Q(s',a') - Q(s,a))$$

- $\gamma$는 Discount factor로 앞선 행동으로 미래에 얻을 보상의 중요도를 나타냄
- $\alpha$는 Learning rate로 딥러닝에서 중요한 개념이며 얼마나 빠르게 Q값을 업데이트 할지를 결정하는 파라미터이다. 너무 높게 설정하게되면 과거의 정보를 무시하고 최근 정보에 의존하는 경향을 보이게 되며 결과값이 수렴하지않는 현상이 발생할 수 있음.
- $argmax_{a'}Q(s',a')$의 의미는 다음 상태(s')에서 가장 높은 Q값을 얻을 수 있는 행동(a')을 선택하겠다는 의미이다. 즉, 미래에 최적의 행동을 의미
*참고, 현재 읽고 있는 논문에서는 벨만 방정식을 살짝 수정한 형태로 나타나있으며 위에 나타난 식과 아주 비슷한 형태를 띄고 있는 것을 볼 수 있다. (벨만방정식에 대해서 좀 더 깊게 찾아보면 확률과 기댓값을 이용해서 표현한 식도 존재하니 궁금하면 찾아보면 좋을 것 같습니다)
시간이 되면 해당 내용에 대해서 Update를 하도록 하겠습니다 ㅠㅠ
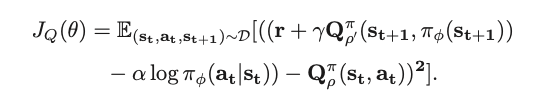
식을 살펴보면 큰 틀은 매우 비슷하고 조금의 형태만 변경한 것을 볼 수 있으며 이로써 강화학습에 대한 포스팅을 마치도록 하겠습니다.
부족한 글이지만 읽어주셔서 감사드리며 피드백을 주신다면 감사하게 수용하도록 하겠습니다. 내용에 대한 질문이나 의견을 제시해주시면 저에게도 큰 도움이 될 것 같습니다.

'Main > 딥러닝' 카테고리의 다른 글
| [논문공부]Diffusion model 코드와 함께 공부하기 - 1 (1) | 2025.04.23 |
|---|